Co-authored by Andrea Goethals & Lee-Anne Raymond
 |
| Adapted from an image credited to TechCrunch |
Was it a record? We had at least 80 participants at our August meetup! This shows the interest in the meetup theme - preserving social media. You can listen to the recording here:
https://youtu.be/wq5YAAhqH8IWe had 3 presenters from New Zealand and Australia talking from different perspectives:
- Gillian Lee, Web Archives Coordinator, NLNZ
- Sean Volke, Online Resources Specialist Librarian, SLNSW
- Gene Melzack, Data Curator, University of Melbourne
Gillian Lee, NLNZ - Ingesting first Twitter dataset
Gillian presented on the truly team effort at NLNZ that went into getting their first Twitter dataset, the 2016 Kaikoura Earthquake, ingested into the National Digital Heritage Archive. It really demonstrated the number of different skills and roles across the Library that were needed for this.
✋ [Chat comment - it's a team effort - so many skills involved!]
The project raised some interesting questions and discussions at the Library. Which things should they preserve? What is an access copy? What does an IE for a Twitter collection look like?
✋ [Chat question from a few people - What is meant by an "IE"? It's an Intellectual Entity, a set of content that is considered a single intellectual unit for purposes of management and description: for example, a particular book, map, photograph, or database.]
And how do you package it for researchers? These were complex questions they had to work through, but now it should be easier to continue their pattern for ongoing Twitter collections.
 |
| Structure of the dataset they came up with |
When deciding how to prepare the data for research use, they looked to Twitter's precedent when they supplied open data using hashes to conceal personal data. When deciding in which of the Library's systems to describe the data, they decided on Tiaki (NLNZ's catalogue for unpublished collections) because the Library had essentially created this dataset, and it provided a better way to describe it than the one used for published collections.
What comes next? They plan to do some social media collecting using
Brandwatch, which allows you to go further back in time, compared to Twarc. Another goal is to automate more of the post-collection processing, for example the associated media collecting, and URL unshortening. Lastly, she wants to make it easier for researchers to access these Library collections.
Links provided by Gillian in the chat:
- https://sfm.readthedocs.io/en/stable/ - Social Feed Manager Tool
- https://natlib.govt.nz/blog/posts/kaikoura-earthquake-collecting-social-media - Blog post about the project
- https://github.com/DocNow/twarc - Twarc
- https://www.docnow.io/ - Documenting the Now
- https://transparency.twitter.com/en/information-operations.html - Twitter's published datasets
- https://github.com/NLNZDigitalPreservation/rosetta_sip_factory - Rosetta SIP Factory
- https://natlib.govt.nz/records/43668067 - Catalog record for the Twitter data
✋ [Chat question - How do you keep a historical record (eg Donald Trumps misinformation / evolving narrative) while respecting people's right to agency over their tweets? The tweet IDs are the access copy - so we're respecting privacy there. Our original dataset includes deleted tweets because we're preserving them and access to these we expect will involve a researcher agreement around ethics, usage of data etc.]
Sean Volke, SLNSW - Collecting social media with Vizie
Sean described a multi-year project at SLNSW to collect social media (Twitter, Facebook, Instagram, and more recently Reddit).
✋ [Chat comment - It’s great that Reddit is part of this project Sean - often overlooked as a social media platform, yet it’s a vibrant internet community. Whenever I use it, I learn something new.]
The project began back in 2012 as a partnership with CSIRO, who developed the tool they use - Vizie. The partnership has continued as CSIRO continue to work on Vizie. The reason they started this project is that they wanted to collect the voices of everyday people in NSW. They don't try to be comprehensive. They mostly focus on NSW but do collect some with broader national focus.
They now have about 184 million posts. This content is stored on the State Library's Amazon Web Service. The collection is multi-lingual - including Chinese, Spanish, Arabic. Lately they have been doing a lot of Covid collecting.
Sean said that it has been tricky to manage the tags they use for the collecting. They don't want the tags to be too broad or they will end up collecting too much. It has been challenging to focus on regional material. Sports tags tend to dominate. They have set up a Social Media Working Group to try to ensure they get diverse input into what tags are used for the collecting, rather than one person deciding.
Vizie only collects current posts. When Sean needs to collect older posts, at least for Twitter, he uses Twarc.
✋ [Chat question - What technologies are you using to collect facebook posts and other social media? We use Vizie for publicly available posts and are investigating targeted collecting (eg, where the user downloads an archive and provides a copy to the Library)]
They have begun experimenting with access to the material. They have an "emotion clock" online that uses the posts to give you an idea of how people are feeling at all hours of the clock.
 |
| Visualisation of current data in the SLNSW Social Media Archive |
Sean left us with some links in the chat:
- VALA Paper: https://www.sl.nsw.gov.au/sites/default/files/BarwickJoseph-VALA.pdf
- Emotion Clock: https://smart.sl.nsw.gov.au/prototype/live.html
- API: https://smart.sl.nsw.gov.au/docs/
- API/DxLabs: https://dxlab.sl.nsw.gov.au/blog/which-way-the-wind-blows/
- Vizie: https://www.sl.nsw.gov.au/research-and-collections/significant-collections/social-media-archive
✋ [Chat question - is it someones job to determine what tags are trending at a given time? Answer from Kieran Hegarty - Yes, working on this today!]
Gene Melzack, UoM - Case study of researchers using social media collections
Gene is a data curator assisting researchers to collect, store, manage and preserve their research data. He talked about a collaboration he has been part of - #DataCreativities. Gene wanted to share this with us so collecting institutions could understand how a particular research group uses a collection like this.
✋ [Chat comment: Yes! researcher voices super valuable]
In early May 2020 he was embedded in a group of Arts and Education researchers who were studying how the creative industries (arts and educators) were adapting to the pandemic conditions. They wanted to use social media as a data source for this research. They wanted to interrogate the information from multiple angles, and then apply it to improving teaching in these conditions.
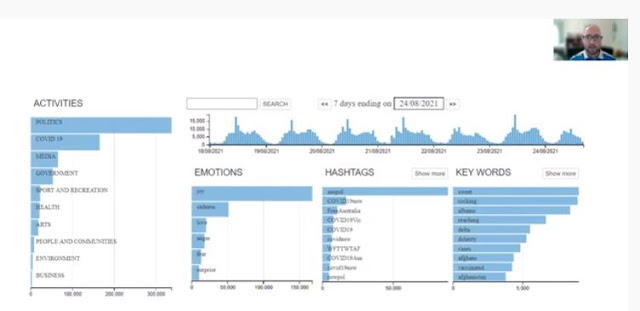 |
| Some features of the Vizie Explorer of the Social Media Archive |
The group used Vizie's Explorer interface to explore their research questions looking at the Social Media Archive created and curated by the State Library NSW. They were particularly interested in the arts category and the emotions. They found this exploration interesting, but limiting for their research. There is a constraint that only lets you see 7 days worth of content, so they weren't able to see the entire Covid span they were interested in. Gene started exploring using the Vizie API to build a dataset specifically for their research.
He was given access to the API and found it very well documented (https://socialmediaarchive.sl.nsw.gov.au/docs/). The documentation is interactive and enabled him to directly enter his queries into the documentation interface. This allowed him to experiment with his queries.
✋ [Chat comment: All the API documentation was developed by CSIRO.]
But unfortunately there were some frustrating things for his use case. There was still the 7 day constraint for retrieving data so he had to write a script to do many separate queries to cover the time period of interest. Because of the large number of queries it was rate-limited and ended up taking 9-10 hours to run.
Another problem for his use case is that there are separate API "end points" for the categories and emotions so he couldn't combine the arts category and emotions in a single API call. They tried to get around this by compiling a list of terms to stand in for the arts category but it wasn't very successful. The data that came back was dominated by sports, as Sean had pointed out earlier. They decided that the curation that the State Library had already done to identify the arts-related posts was more accurate than what thy were able to do with their own queries.
✋ [Chat comment: The skew may also represent popularity of sport/politics over other activities]
Besides the big data exploration, they were also interested in close reading. The Vizie Explorer interface proved very useful for identifying where to start on this. In the arts category they identified a tag very relevant to their research - #AusLibChat. It's used by students / new graduates in education talking about issues on social media. So they went back and looked at this tag during the first 3 months of lockdown. They found the keywords gave insight into this time - housebound, online, zoom, cats. And they could see a range of emotions during this time.
✋ [Chat comment: FYI - #AusLibChat was founded by ALIA's New Generation Advisory Committee (NGAC). NGAC hosts monthly discussions on Twitter using the hashtag (open to all!)]
So in the end, the Explorer interface was more useful to their research than having API access.
Gene recommended we read:
- Acker, A., & Kreisberg, A. (2020). Social media data archives in an API-driven world. Archival Science, 20(2), 105-123. doi.org/10.1007/s10502-019-09325-9 – Kieran Hegarty SLNSW – Key underlying principles around applying access in the GLAM space being the platforms concerns are more profit driven.
We didn't have time to talk about it, but this peaked our interest for discussing another time:
✋ [Chat comment from Matthew Burgess: There have been issues with API access to platforms that has skewed the data, so it's something we need to look at documenting as part of provenance. Eg, changes to platform APIs meaning no data captured for a certain period]
A final question for all our speakers
What would you have done differently?
Each of them talked about how tricky it was to choose tags for their collecting.
- Sean would have been more careful with tags (he crashed Vizie at one point because of tags that weren't scoped narrowly enough.)
- Gillian said that its hard to get the scoping right when using Twarc - don't want too narrow of a scope, but also don't want to collect too much.
- If he were to do it over, Gene would have been more systematic about documenting what he did as part of his exploration (dates, tags, etc.).
Closing
Our final meetup of the year will be in November - be on the lookout for that.
World Digital Preservation Day is coming up on 4 November. We can use the forum to share how we plan to celebrate. You could put a call out for collaboration, share your baking, whatever you can think of to celebrate the day.








{kind=link}
0 Comments